On January 9, the Shanghai Artificial Intelligence Laboratory (Shanghai AI Laboratory) and members of the Large Model Corpus Data Alliance released the "Wanjuan Silk Road" multilingual pre-trained corpus to provide high-quality data support for multilingual large model training.
As the joint construction of the Belt and Road Initiative enters a new stage of high-quality development, scientific and technological innovation and cooperation will play a more critical role. The Shanghai AI Laboratory explores the use of artificial intelligence to enable high-quality joint construction of the Belt and Road Initiative through the development of advanced data intelligence technologies and the provision of multilingual corpora.
The first phase of "Wanjuan Silk Road" has open-sourced corpora in five languages, including Thai, Russian, Arabic, Korean, and Vietnamese, with a total size of over 1.2TB (each language exceeds 150GB), and a total number of tokens exceeding 300B, covering data in seven major areas, including life, encyclopedia, culture, and news in countries and regions where the above languages are used.
Data is an important infrastructure for artificial intelligence, and data quality is one of the key factors that determine the application capabilities of artificial intelligence. As a comprehensive text corpus, "Wanjuan·Silk Road" collects online public information, documents, patents and other materials from multiple countries and regions. The total data size exceeds 1.2TB, and the total number of tokens exceeds 300B (300 billion), which is at the international leading level. The first open-source corpus mainly consists of five subsets: Thai, Russian, Arabic, Korean and Vietnamese, and the data size of each subset exceeds 150GB.
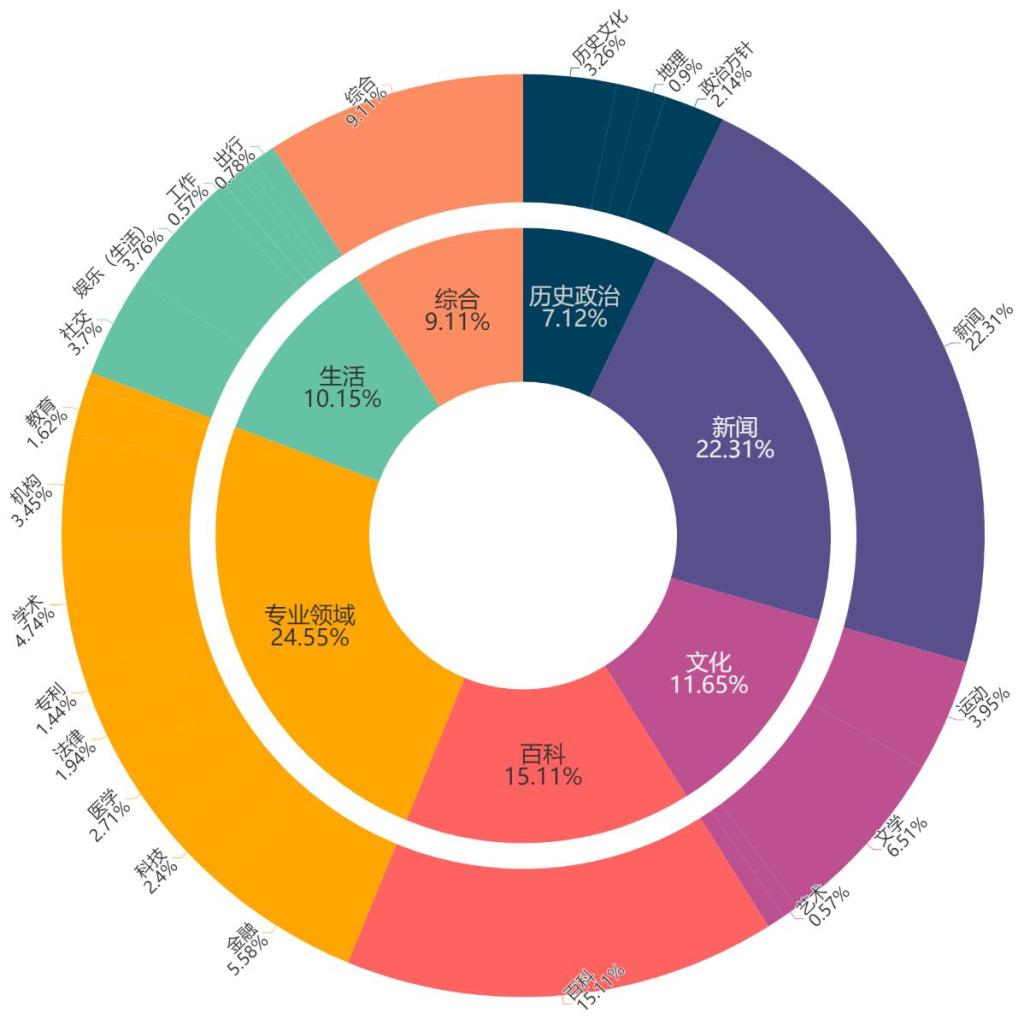
Based on the "Shusheng·Pu Yu" intelligent label classification system, the research team subdivided each corpus subset into 7 major categories and 32 minor categories, covering history, politics, culture, real estate, shopping, weather, catering, encyclopedia, professional knowledge and other categories with language location characteristics, which makes it convenient for researchers to retrieve data according to specific needs and can adapt to the diverse needs of different research fields.
Classification of subsets of the “Wanjuan·Silk Road” corpus (7 major categories and 32 minor categories in total, only some labels are shown in the chart)
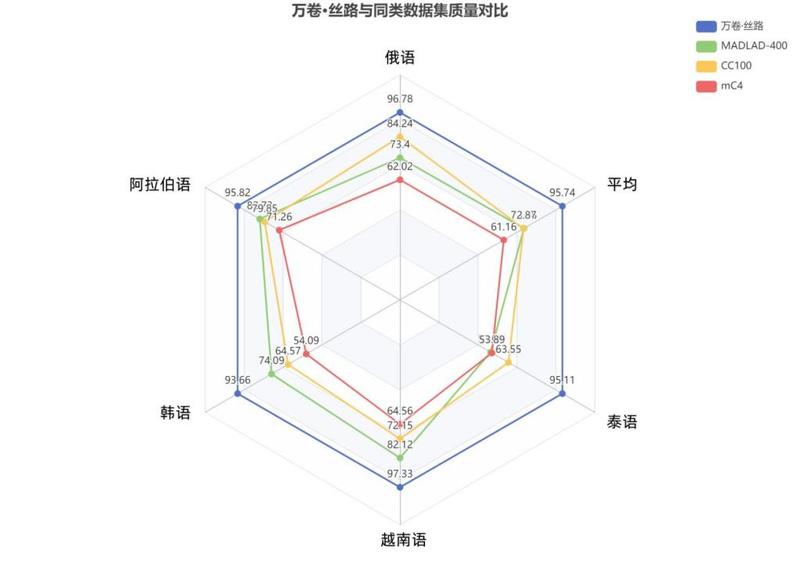
Through manual annotation by experts, the "Wanjuan Silk Road" corpus has established a text data quality assessment system with seven dimensions to ensure high standards and high quality of data in terms of completeness, validity, comprehensibility, fluency, relevance, similarity and security.
By using Dingo (https://github.com/DataEval/dingo), an open source tool for data quality assessment based on a large language model, the research team conducted a comprehensive assessment of the data quality of "Wan Juan Silk Road" from multiple dimensions. The results showed that all five subsets received excellent comprehensive scores.
The Large Model Corpus Data Alliance was jointly initiated by the Shanghai Artificial Intelligence Laboratory and 10 other units including China Media Group, People's Daily Online, National Meteorological Center, Chinese Institute of Scientific and Technological Information, Shanghai Media Group, and Shanghai Media Group.